

A Learning Machine?
Machine Learning(ML) is a subset of Artificial Intelligence. It focuses on learning from the data without being explicitly programmed. So, you might be wondering how does it happen? How can a machine which was built to be programmed explicitly started to learn things on its own? The answer is not that straightforward but is a confounded one but I will try to make it simple. It tries to make decisions with minimal need for human intervention by identifying patterns from the data; statistics and powerful ML algorithms have made it possible to achieve such a feat.
The terms machine learning and artificial intelligence were coined around the 1960s so the algorithms and maths behind it had been present for so long then why there is so much buzz about it right now? To train machine learning algorithms you need data, lots of data. Now in the era of big data, we have what it needs to train the machine. Before diving into topic lets first acquire some knowledge about data and how it is classified.
Bits and Bytes about Data
Data can be classified based on various factors, such as structure, numerical or categorical. For the scope of this topic, we discuss labeled data and unlabeled data. Data is simply information about something. For example, consider a table consisting of information about cats. The columns describe the characteristics of the cat such as color, the size, the weight and the breed. Let us call these columns as features describing the cat. Some features are special and we call them as labels here, in this case, the breed of the cat. This is called as labelled data and if there are no special features in the data we call it unlabeled data.
Supervised Learning
As the name suggests is supervising the machine while it learns. It is used in classification and regression. Classification is the task where the machine classifies the problem into classes for example if a patient has a disease or not if an email is a spam or not. One of the classic examples of regression is predicting house prices. Some of the important attributes can be the number of rooms, locality, amenities, etc. In supervised learning, we need labelled data.
Extending further the example of predicting house prices using various attributes using human intuition. If there the house in a locality where there are schools, and the essential stores nearby it is probably going to be costly. In a similar way, as the number of rooms increases the prices rise as well as if the house is well equipped with luxurious amenities. Continuing with same intuition in supervised learning using mathematical equations we try to model it. There is a direct proportionality between prices and number of rooms so it assigns weights to it accordingly.
There are two techniques – Regression, it predicts a single value using the labelled data. Classification is used to group the output into a class. Example – If an image is of cat or dog.
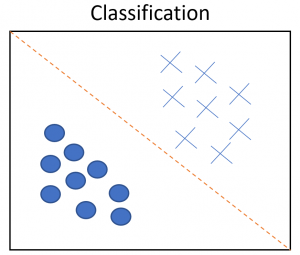
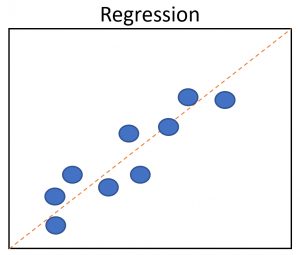
The different types of supervised learning algorithms are:
- Linear Regression
- Logistic Regression
- Decision Trees
- Random Forest
- Support Vector Machine
Unsupervised Learning
As in contrast, unsupervised learning is used generally when we don’t have labelled data. We try to find patterns or clusters present in the data. Let us consider an example of purchasing behaviors of customers. Customers can be grouped into clusters based on their purchasing habits. Some might just buy veggies not dairy products so while some may buy fewer veggies but more meat. So we can cluster the customers into vegans, vegetarians and the ones who eat meat. Using clustering technique we try to find patterns in the purchasing behavior of the customers.
It can be further grouped into Clustering which deals with finding groups in an uncategorized data. We can get an idea about the number of clusters present in the group in the dataset by plotting the data. Association is the technique of finding interesting relationships between variables in a large database. For example, people who buy onions, tomatoes, potatoes and burger buns are most likely to buy cold drinks and beer with it.
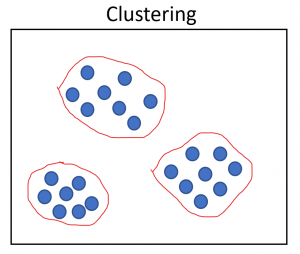
The different types of unsupervised learning algorithms are:
- k-means clustering
- Hierarchical clustering
- Density-based spatial clustering of applications with noise(DBSCAN)
Summary
In this post, you learned the difference between supervised learning and unsupervised learning. There are two more types, reinforcement learning and semi-supervised learning which we will be discussed in the next post. The major differences have been highlighted in the table below.
